 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBack to Parsimonious Latents: Learning Task-Centric World Models from Visual Foundations
May 25, 2026World models enable agents to predict future dynamics conditioned on actions, making the choice of latent representation central to planning and control. Such representations are often either learned directly from pixels with limited semantic structure or inherited from frozen visual foundation models with excessive task-irrelevant detail, yielding state spaces that are poorly matched to downstream planning and control. This is especially challenging in reward-free offline settings, where the model must learn from fixed trajectories without reward supervision or online interaction. To address this, we propose TC-WM, a framework for turning foundation-model embeddings into compact, task-sufficient world representations. The key design is to treat the pretrained embedding space as a semantic scaffold rather than as the final state space: TC-WM linearly projects high-dimensional visual embeddings into a compact latent as the dynamic space, aligns a subspace with the agent's physical state via contrastive learning, and reconstructs embeddings to preserve useful visual structure. This combines the generality of foundation features with the controllability of task-centric dynamics. Theoretically, we show that TC-WM suffices to identify the underlying task-centric latent factors up to a simple transformation. Empirically, TC-WM enables test-time planning across diverse environments (e.g., Robomimic and D4RL), achieving better world-modeling quality and more precise control than state-of-the-art approaches.
From Generalist to Specialist Representation
May 12, 2026Given a generalist model, learning a task-relevant specialist representation is fundamental for downstream applications. Identifiability, the asymptotic guarantee of recovering the ground-truth representation, is critical because it sets the ultimate limit of any model, even with infinite data and computation. We study this problem in a completely nonparametric setting, without relying on interventions, parametric forms, or structural constraints. We first prove that the structure between time steps and tasks is identifiable in a fully unsupervised manner, even when sequences lack strict temporal dependence and may exhibit disconnections, and task assignments can follow arbitrarily complex and interleaving structures. We then prove that, within each time step, the task-relevant latent representation can be disentangled from the irrelevant part under a simple sparsity regularization, without any additional information or parametric constraints. Together, these results establish a hierarchical foundation: task structure is identifiable across time steps, and task-relevant latent representations are identifiable within each step. To our knowledge, each result provides a first general nonparametric identifiability guarantee, and together they mark a step toward provably moving from generalist to specialist models.
RPM-Net Reciprocal Point MLP Network for Unknown Network Security Threat Detection
Apr 08, 2026Effective detection of unknown network security threats in multi-class imbalanced environments is critical for maintaining cyberspace security. Current methods focus on learning class representations but face challenges with unknown threat detection, class imbalance, and lack of interpretability, limiting their practical use. To address this, we propose RPM-Net, a novel framework that introduces reciprocal point mechanism to learn "non-class" representations for each known attack category, coupled with adversarial margin constraints that provide geometric interpretability for unknown threat detection. RPM-Net++ further enhances performance through Fisher discriminant regularization. Experimental results show that RPM-Net achieves superior performance across multiple metrics including F1-score, AUROC, and AUPR-OUT, significantly outperforming existing methods and offering practical value for real-world network security applications. Our code is available at:https://github.com/chiachen-chang/RPM-Net
World Action Verifier: Self-Improving World Models via Forward-Inverse Asymmetry
Apr 02, 2026General-purpose world models promise scalable policy evaluation, optimization, and planning, yet achieving the required level of robustness remains challenging. Unlike policy learning, which primarily focuses on optimal actions, a world model must be reliable over a much broader range of suboptimal actions, which are often insufficiently covered by action-labeled interaction data. To address this challenge, we propose World Action Verifier (WAV), a framework that enables world models to identify their own prediction errors and self-improve. The key idea is to decompose action-conditioned state prediction into two factors -- state plausibility and action reachability -- and verify each separately. We show that these verification problems can be substantially easier than predicting future states due to two underlying asymmetries: the broader availability of action-free data and the lower dimensionality of action-relevant features. Leveraging these asymmetries, we augment a world model with (i) a diverse subgoal generator obtained from video corpora and (ii) a sparse inverse model that infers actions from a subset of state features. By enforcing cycle consistency among generated subgoals, inferred actions, and forward rollouts, WAV provides an effective verification mechanism in under-explored regimes, where existing methods typically fail. Across nine tasks spanning MiniGrid, RoboMimic, and ManiSkill, our method achieves 2x higher sample efficiency while improving downstream policy performance by 18%.
KoopmanFlow: Spectrally Decoupled Generative Control Policy via Koopman Structural Bias
Mar 14, 2026Generative Control Policies (GCPs) show immense promise in robotic manipulation but struggle to simultaneously model stable global motions and high-frequency local corrections. While modern architectures extract multi-scale spatial features, their underlying Probability Flow ODEs apply a uniform temporal integration schedule. Compressed to a single step for real-time Receding Horizon Control (RHC), uniform ODE solvers mathematically smooth over sparse, high-frequency transients entangled within low-frequency steady states. To decouple these dynamics without accumulating pipelined errors, we introduce KoopmanFlow, a parameter-efficient generative policy guided by a Koopman-inspired structural inductive bias. Operating in a unified multimodal latent space with visual context, KoopmanFlow bifurcates generation at the terminal stage. Because visual conditioning occurs before spectral decomposition, both branches are visually guided yet temporally specialized. A macroscopic branch anchors slow-varying trajectories via single-step Consistency Training, while a transient branch uses Flow Matching to isolate high-frequency residuals stimulated by sudden visual cues (e.g., contacts or occlusions). Guided by an explicit spectral prior and optimized via a novel asymmetric consistency objective, KoopmanFlow establishes a fused co-training mechanism. This allows the variant branch to absorb localized dynamics without multi-stage error accumulation. Extensive experiments show KoopmanFlow significantly outperforms state-of-the-art baselines in contact-rich tasks requiring agile disturbance rejection. By trading a surplus latency buffer for a richer structural prior, KoopmanFlow achieves superior control fidelity and parameter efficiency within real-time deployment limits.
On Information Self-Locking in Reinforcement Learning for Active Reasoning of LLM agents
Mar 12, 2026Reinforcement learning (RL) with outcome-based rewards has achieved significant success in training large language model (LLM) agents for complex reasoning tasks. However, in active reasoning where agents need to strategically ask questions to acquire task-relevant information, we find that LLM agents trained with RL often suffer from information self-locking: the agent ceases to ask informative questions and struggles to internalize already-obtained information. To understand the phenomenon, we decompose active reasoning into two core capabilities: Action Selection (AS), which determines the observation stream through queries, and Belief Tracking (BT), which updates the agent's belief based on collected evidence. We show that deficient AS and BT capabilities will limit the information exploration during RL training. Furthermore, insufficient exploration in turn hinders the improvement of AS and BT, creating a feedback loop that locks the agent in a low-information regime. To resolve the issue, we propose a simple yet effective approach that reallocates the learning signal by injecting easy- to-obtain directional critiques to help the agent escape self-locking. Extensive experiments with 7 datasets show that our approach significantly mitigates the information self-locking, bringing up to 60% improvements.
Factored Causal Representation Learning for Robust Reward Modeling in RLHF
Jan 29, 2026A reliable reward model is essential for aligning large language models with human preferences through reinforcement learning from human feedback. However, standard reward models are susceptible to spurious features that are not causally related to human labels. This can lead to reward hacking, where high predicted reward does not translate into better behavior. In this work, we address this problem from a causal perspective by proposing a factored representation learning framework that decomposes the model's contextual embedding into (1) causal factors that are sufficient for reward prediction and (2) non-causal factors that capture reward-irrelevant attributes such as length or sycophantic bias. The reward head is then constrained to depend only on the causal component. In addition, we introduce an adversarial head trained to predict reward from the non-causal factors, while applying gradient reversal to discourage them from encoding reward-relevant information. Experiments on both mathematical and dialogue tasks demonstrate that our method learns more robust reward models and consistently improves downstream RLHF performance over state-of-the-art baselines. Analyses on length and sycophantic bias further validate the effectiveness of our method in mitigating reward hacking behaviors.
DEPTH: Hallucination-Free Relation Extraction via Dependency-Aware Sentence Simplification and Two-tiered Hierarchical Refinement
Aug 20, 2025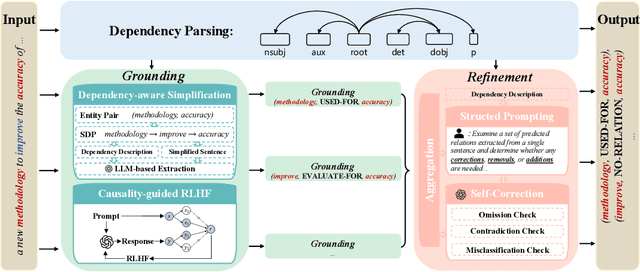

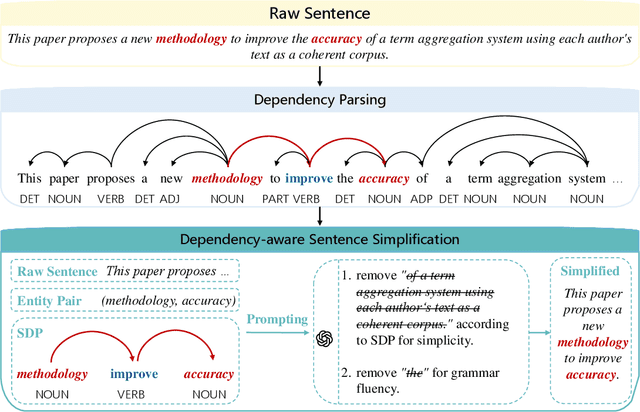

Relation extraction enables the construction of structured knowledge for many downstream applications. While large language models (LLMs) have shown great promise in this domain, most existing methods concentrate on relation classification, which predicts the semantic relation type between a related entity pair. However, we observe that LLMs often struggle to reliably determine whether a relation exists, especially in cases involving complex sentence structures or intricate semantics, which leads to spurious predictions. Such hallucinations can introduce noisy edges in knowledge graphs, compromising the integrity of structured knowledge and downstream reliability. To address these challenges, we propose DEPTH, a framework that integrates Dependency-aware sEntence simPlification and Two-tiered Hierarchical refinement into the relation extraction pipeline. Given a sentence and its candidate entity pairs, DEPTH operates in two stages: (1) the Grounding module extracts relations for each pair by leveraging their shortest dependency path, distilling the sentence into a minimal yet coherent relational context that reduces syntactic noise while preserving key semantics; (2) the Refinement module aggregates all local predictions and revises them based on a holistic understanding of the sentence, correcting omissions and inconsistencies. We further introduce a causality-driven reward model that mitigates reward hacking by disentangling spurious correlations, enabling robust fine-tuning via reinforcement learning with human feedback. Experiments on six benchmarks demonstrate that DEPTH reduces the average hallucination rate to 7.0\% while achieving a 17.2\% improvement in average F1 score over state-of-the-art baselines.
Null Counterfactual Factor Interactions for Goal-Conditioned Reinforcement Learning
May 06, 2025



Hindsight relabeling is a powerful tool for overcoming sparsity in goal-conditioned reinforcement learning (GCRL), especially in certain domains such as navigation and locomotion. However, hindsight relabeling can struggle in object-centric domains. For example, suppose that the goal space consists of a robotic arm pushing a particular target block to a goal location. In this case, hindsight relabeling will give high rewards to any trajectory that does not interact with the block. However, these behaviors are only useful when the object is already at the goal -- an extremely rare case in practice. A dataset dominated by these kinds of trajectories can complicate learning and lead to failures. In object-centric domains, one key intuition is that meaningful trajectories are often characterized by object-object interactions such as pushing the block with the gripper. To leverage this intuition, we introduce Hindsight Relabeling using Interactions (HInt), which combines interactions with hindsight relabeling to improve the sample efficiency of downstream RL. However because interactions do not have a consensus statistical definition tractable for downstream GCRL, we propose a definition of interactions based on the concept of null counterfactual: a cause object is interacting with a target object if, in a world where the cause object did not exist, the target object would have different transition dynamics. We leverage this definition to infer interactions in Null Counterfactual Interaction Inference (NCII), which uses a "nulling'' operation with a learned model to infer interactions. NCII is able to achieve significantly improved interaction inference accuracy in both simple linear dynamics domains and dynamic robotic domains in Robosuite, Robot Air Hockey, and Franka Kitchen and HInt improves sample efficiency by up to 4x.
* Published at ICLR 2025
Generative AI Application for Building Industry
Oct 01, 2024



This paper investigates the transformative potential of generative AI technologies, particularly large language models (LLMs), within the building industry. By leveraging these advanced AI tools, the study explores their application across key areas such as energy code compliance, building design optimization, and workforce training. The research highlights how LLMs can automate labor-intensive processes, significantly improving efficiency, accuracy, and safety in building practices. The paper also addresses the challenges associated with interpreting complex visual and textual data in architectural plans and regulatory codes, proposing innovative solutions to enhance AI-driven compliance checking and design processes. Additionally, the study considers the broader implications of AI integration, including the development of AI-powered tools for comprehensive code compliance across various regulatory domains and the potential for AI to revolutionize workforce training through realistic simulations. This paper provides a comprehensive analysis of the current capabilities of generative AI in the building industry while outlining future directions for research and development, aiming to pave the way for smarter, more sustainable, and responsive construction practices.